
Latent Space Exploration in VAEs using Image and Tabular Data
Georgio Angelo
Supervisors: Assoc Prof Catarina Pinto Moreira and Assoc Prof Chun Ouyang
Unlike traditional Autoencoders which encode input into single data point, Variational Autoencoders (VAEs) captures variability by encoding probabilistic distribution of an input into the latent space.
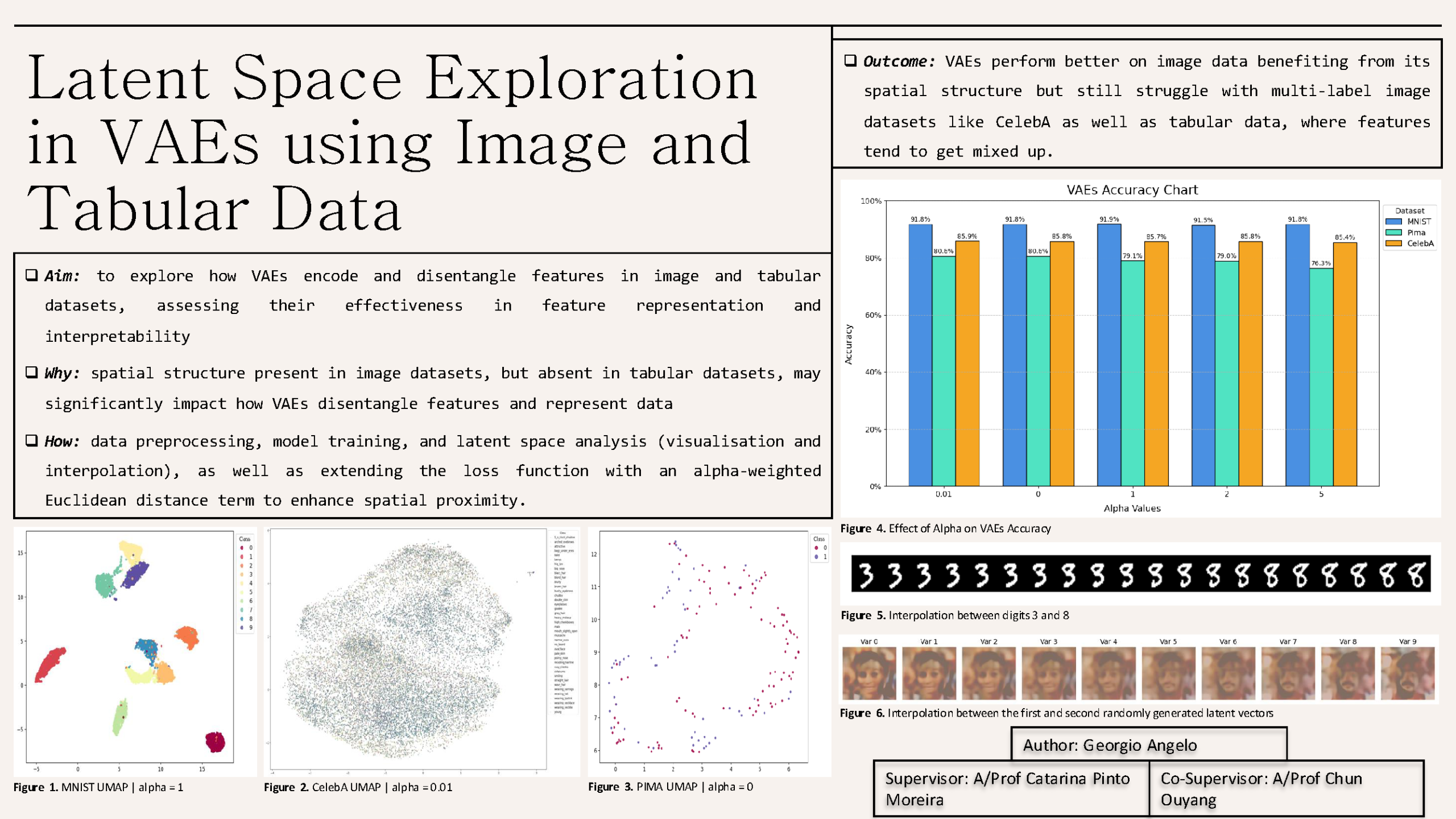
This project aims to explore how VAEs encode and disentangle features in both image and tabular datasets, evaluating their effectiveness in feature representation and interpretability across these data types. We built VAEs with different architectures for each dataset, using convolutional layers for image (MNIST and CelebA) and fully connected layers for tabular (Pima) data.
Through preprocessing, data cleaning, and latent space analyses which involved visualisation and interpolation, we assessed how VAEs captured and represented underlying data features. To further improve the reconstruction fidelity, we extended the VAE loss function by adding a term that measures the Euclidean distance between the original data vector and its reconstruction candidate, weighted by a parameter alpha, thereby emphasizing spatial proximity in the latent space.
We conducted this study to understand VAEs’ strengths and limitations, especially when applied to different types of data. Our goal was to uncover how the latent space representations of VAEs vary between image data, which has spatial structure, and tabular data, which lacks such structure.
Our findings show that VAEs perform significantly better on image data, benefiting from its inherent spatial structure and high dimensionality that allows for effective disentanglement of features such as object shape and color. In contrast, VAEs seem to struggle with tabular data due to the absence of spatial structure, which leads to less interpretable latent representations. While it can disentangle features like categorical and continuous variables, relationships between features can be hard to separate, resulting in entanglement in the latent space.
We also found that feature disentangling becomes more challenging for the multi-label datasets, as VAEs would mistakenly encode labels that often appear together into the same latent dimension.
Media Attributions
- Latent space exploration in VAEs using image and tabular data © Georgio Angelo is licensed under a CC BY-NC (Attribution NonCommercial) license
